
sql 语句不区分大小写,关键字建议使用大写
一条 sql 语句以分号结尾
注释:
sql 分类:





查询当前数据库中的所有表:show tables;
查询表结构: desc 表名;
查询指定表的建表语句: show create table 表名;
创建表:create table

表修改:alter
添加字段:
修改字段:


删除字段:

修改表名:

删除表:

删除表并重新创建该表

增删改 insert delete update


如果没有 where 条件,则会修改整张表的数据

如果没写 where 条件,就会删除表中所有数据
delete 不能用于删除某行某个字段的数据,只能删除行
select
编写顺序:

执行顺序:from -> where -> group by -> select -> order by -> limit
查询多个字段

设置字段别名

去除重复记录





count:统计数量
max:最大值
min:最小值
avg:平均值
sum:求和
注:所有 NULL 值不参与聚合函数的运算

分组查询返回的字段一般是分组的字段以及聚合函数
where 和 having 条件的区别:
执行时机不同,where 分组前过滤,having 分组后过滤
where 不能使用聚合函数进行判断,而 having 可以

排序方式:asc(升序,默认值)、desc(降序)
对多个字段进行排序,先按第一个字段进行排序,如果有相同的,再按第二个字段,以此类推

索引和数组索引一样,是从 0 开始的,索引的计算也相同
不同数据库使用的关键字不相同
若起始索引是 0,可以省略
用户管理

用户信息存放在 mysql 数据库的 user 表中

主机名指的是在哪个主机上可以以此用户的身份对数据库进行访问
可以使用通配符 % 来表示任意主机
此时该用户没有任何权限


权限控制
权限如下:



可以使用 * 来表示所有数据库名或表名,即 *.* 表示所有数据库和表

若要授予所有权限,那么权限列表填
all就行多个权限之间用逗号隔开



type 是时间单位 day、month、year 等

可以跟多个 when


约束:作用于表中字段上的规则,用于限制存储在表中的数据
保证数据的正确性、有效性和完整性

可以在创建表或修改表的时候添加约束
如:


外键约束:
将具有外键的表称为子表,外键所关联的表称为父表
添加外键:

如:
删除外键:

外键约束字段在删除、更新数据时的行为:(no action 和 restrict 是默认行为)


比如部门表和员工表之间,一个部门有很多员工,通常通过在多的表中(员工表)设置外键
比如学生和选课表之间的关系,一个学生可以选多门课,而一门课可以被多个学生选择,要记录这种关系,需要建立第三张中间表,至少包含两个外键,分别关联学生表和课程表的主键
如用户和用户信息之间的关系
一对一的关系多用于单表拆分,将基础字段放在一张表,详细信息字段放在另一张表,可以提升操作效率
如何维护两者之间的关系:在任意一张表加外键,关联另外一张表的主键,并将外键设置为 unique



如:



查 表 1 所有 + 表 1、2 交集部分数据

查 表 2 所有 + 表 1、2 交集部分数据
如:

左外和右外可以转化,交换表顺序就行,一般使用左外就行

自连接可以是内连接查询也可以是外连接查询
必须给表起别名,把一张表看作两张表
通常用于一张表中的两字段有对应关系,如员工对应领导
如:
内连接

左外连接

把多次查询的结果合并起来,形成一个新的查询结果集

union all:直接将查询的结果合并(不去重)
union:将查询的结果合并后去重
联合查询的使用,查询的字段数以及字段数据类型必须相同
sql 语句嵌套 select

外部语句可以是 insert update delete select 的任何一个

根据子查询的位置,分为 where 之后、from 之后、select 之后
子查询返回的结果是单个值,即一行一列
常用操作符: = != <= >= < > 等


子查询返回结果是一列(不限制行数)
常用操作符:in、not in、any、some、all

如:



返回结果是一行,可以是多列。
常用操作符:=、!=、in、not in

返回结果多行多列
一般用于将查询结果作为子表,然后在子表中查询
常用操作符:in


事务:一组操作的集合,事务会将所有操作视为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功要么同时失败
典型例子:转账问题
张三 --> 李四,先检查张三是否有 1000,若有,-1000,李四+1000
mysql 中的事务默认自动提交,即当执行一条 DML 语句时,mysql 会立即隐式的提交事务
因此需要手动的开启事务、提交事务以及回滚事务
查看事务提交方式:
select @@autocommit
方式一:设置事务提交方式:
设置事务提交方式:0 为手动提交,默认 1 自动提交
set @@autocommit = 0
提交事务:
commit
回滚事务:
rollback
感觉像 git,执行事务只是保存到暂存区,只有 commit 后才放到本地仓库,且执行的结果不满意也可以进行 reset
方式二:开启事务
开启事务:
start transaction 或者 begin
提交:commit
回滚:rollback



查看事务隔离级别:
select @@transaction_isolation
设置事务隔离级别:

session:仅针对当前会话有效
事务隔离级别越高,数据越安全,但是性能越低


存储引擎:决定了存储数据、建立索引、更新/查询数据等技术的实现方式
存储引擎是基于表的,也就是不同表可以使用不同存储引擎,所以存储引擎也被称为表类型
在创建表时可以指定存储引擎

查看当前数据库支持的存储引擎
show engines

后面三个字段为:是否支持事务、是否只是 XA 协议、是否支持保持点
是一种兼顾高性能和高可靠性的存储引擎,在 MySQL5.5 后作为默认存储引擎
特点:支持事务、行级锁以及外键
文件存储:
文件名:表名.ibd,
InnoDB 的每张表都会对应这样的一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引
innodb_file_per_table该参数决定是否每个表空间都对应一个文件,一般默认每个都对应一个文件frm 是早期的表结构存储,sdi 是后来的表结构存储
在 cmd 命令下行输入 idb2sdi 文件名,会显示一大串 json,其中是表结构
InnoDB 的逻辑存储结构

区(extent)的大小为 1MB,页(page)的大小为 16KB,一个区包含 64 个页
是 MySQL 早期的存储引擎
特点:不支持事务、不支持外键、不支持行级锁、支持表锁,访问速度快
文件存储:

表数据存储在内存中,只能作为临时表或缓存使用,因为断电数据会消失
特点:内存存放,读取快,支持 hash 索引
文件存储:xxx.sdi 存储表结构信息,因为数据都放在内存

特别是要清楚 InnoDB 和 MyISAM 的三大区别:
InnoDB 支持事务、行锁和外键,而 MyISAM 都不支持,支持表锁

绝大多数情况选择 InnoDB
而适合使用 MyISAM 的应用场景已经被 nosql 的 mongoDB 取代
适合 Memory 的应用场景被 redis 取代
索引是一种数据结构,用来高效获取数据
优点:
缺点:
缺点可以忽略,因为磁盘成本低,且正常业务系统应该是查询的次数远大于增删改
mysql 的索引是在存储引擎层实现的,不同存储引擎具有不同的索引结构


平时说的索引结构,一般只要没有特别指明,都是 B+树索引
B+树的特点:

mysql 索引结构对 B+树进行了优化,使得叶子节点形成双向链表
数据存储在叶子节点,其他节点只用于索引

mysql 的 hash 索引结构

在 MySQL 中只有 Memory 引擎支持 hash 索引,但是
InnoDB 具有 hash 自适应功能,在指定条件下,会通过 B+树自动构建 hash 索引



二级索引又称为辅助索引、非聚集索引
聚集索引的自动选取规则:
rowid 作为隐藏的聚集索引
聚集索引的叶子节点存储一行的数据
二级索引的叶子节点存储ID
那么查询的时候是如何工作的呢: 回表查询
如: select * from user where name = 'Lily'
首先在 name 字段对应的二级索引查询到名字对应的 ID 值,然后使用 ID 值在聚集索引中查询一行的数据并返回,称之为回表查询
思考:
select * from user where id = 10
select * from user where name = 'Lily'
以上两个查询哪个效率高:
答:第一个效率更高,直接查询 id 只需要在聚集索引中查找,不需要回表查询;而查询名字,需要先查找二级索引获得 id 再对聚集索引查询

创建索引:

创建常规索引不需要在 INDEX 前添加类型
一个索引可以关联多个字段
只关联一个字段的索引称为单列索引
关联多个字段的索引称为组合索引或联合索引
查看索引:

删除索引:

mysql 提供了以下命令来查看语句执行的次数
show global/session status like'Com_______'
global 为全局,session 为当前会话
通过此命令得知当前数据库占大多数的操作是什么,并针对此进行优化

慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位秒,默认 10 秒)的所有 sql 语句操作
查询慢查询日志功能是否开启:
show variables like'slow_query_log';默认未开启
需要在 MySQL 的配置文件
/etc/my.cnf中配置如下信息来打开慢查询日志功能

慢查询日志文件 /var/lib/mysql/localhost-slow.log
通过查看该文件来查询执行效率低的 sql 操作
show profiles 能够在 sql 优化时,帮助我们了解某条 sql 语句的具体耗时,以及时间都耗在哪
select @@have_profiling来查看当前数据库是否支持 profile 详情
select @@profiling查看当前数据库是否开启 profile默认关闭,
set profiling = 1来打开 profile 详情

查看指定 query_id 的 sql 操作在各个阶段的耗时情况:
show profile for query query_id
query_id 在
show profiles中查看

使用 explain 或 desc 可以获取 MySQL 如何执行 sql 语句的信息,如执行过程中表如何连接、连接顺序,索引等




优化目标:type 尽量往前,
system:系统表
const:主键或唯一约束的字段
ref:通常是不唯一字段
all:全表扫描,性能最低
对于联合索引即关联了多个列的索引要遵循最左前缀法则
最左前缀法则:查询中,索引最左边的列必须存在,并且不跳过索引中的列。
若跳跃了某一列,该列后的字段索引将会失效
指的是 where 之后的语句要遵循最左前缀法则,但是字段顺序无关,即只要存在最左列字段,且不跳过中间字段就行
对于范围查询来说,where 中的条件若出现了范围查询,范围查询后面的条件将不会使用索引来查询,而它前面的依然是索引
如联合索引的字段顺序为:profession、age、status
select * from tb_usr where profesion = '软件工程'and age = 30 and status = '0'
上述语句索引有效
select * from tb_usr where age = 30 and profesion = '软件工程'and status = '0'
上述语句只是交换了顺序,索引仍然有效
select * from tb_usr where profesion = '软件工程'and status = '0'
上述语句 where 条件中间的 age 没有,因此索引失效
select * from tb_usr where age = 30 and profesion = '软件工程'
上述语句索引有效,满足最左前缀法则。
那么对于以下查询
select * from tb_usr where profesion = '软件工程'and age > 30 and status = '0'
age>30 为范围查询,那么他后面 status='0' 的索引将失效,而它前面的 profession 依然生效
如果将**>**改为**>=**,那么索引就生效
如:字段 phone 已建立索引
select * from tb_user where substring(phone,10,2) = '15'
以上 sql 查询语句索引失效,type 为全表扫描
因此尽量不要在索引列上进行运算操作
'',索引失效select * from tb_user where phone = 15829585395
以上查询失效,因为 phone 是字符串类型
上述语句可以正常查询出来
对尾部进行模糊匹配不失效,对头部进行模糊匹配则索引失效
select * from tb_user where phone like'158%'
上述索引不失效
select * from tb_user where phone like'%5395'
上述索引失效
or 连接的条件,只有所有条件都有索引,索引才会生效select * from tb_user where phone = '15829585395'or age =12
上述索引失效,由于联合索引的字段顺序为:profession、age、status,上述查询不遵循最左前缀法则
如果 MySQL 评估使用索引比全表扫描更慢,那么就不会使用索引
也就是对于索引列,若满足条件的行绝大多数,即返回的行占总的绝大多数,那么 MySQL 会认为全表扫描更快,反之返回行占少数,那么就会使用索引

use 是建议 MySQL
force 是强制
尽量减少使用 select *,使用覆盖索引,即返回的字段被包含在使用的索引中
本质是避免回表查询,回表查询会降低效率
除非是使用 id 即主键,聚集索引查询,
select *也只需要一次查询,不需要回表查询

上面的这个指的是
explain中的extra字段

思考:

建立 username 和 password 的联合索引,这样就不用回表查询
针对的问题:当字段类型为字符串(varchar,text 等),时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘 IO,影响查询效率。
此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。

前缀长度的选取:

尽量保证字符串长度更小和选择性更大的平衡
前缀索引的查询流程:
去前缀构建辅助索引后,查询时,在辅助索引时先搜索到 id,然后在聚集索引进行回表查询,找到对应 ID,对比查询条件是否成立,不成立则将辅助索引的叶子节点的下一个节点 ID 进行回表查询(B+树叶子节点是链表),知道匹配查询条件

在业务场景中,如果涉及多个查询条件,当要对查询字段建立索引时,建议建立联合索引
如: select id,phone,name from user_tb where phone = '123123312'and name = 'fdlajsk'
且 phone 和 name 各自有一个单列索引,那么 MySQL 只会选择评估效率比较高的一个索引来查询,然后进行回表查询匹配 name 的条件,并返回
而建立 phone 和 name 的联合索引,就不需要回表查询
联合索引的 B+树形式:

性别类似的字段只有男女,不如不建
对于小规模数据插入的优化:

大规模数据的插入:load
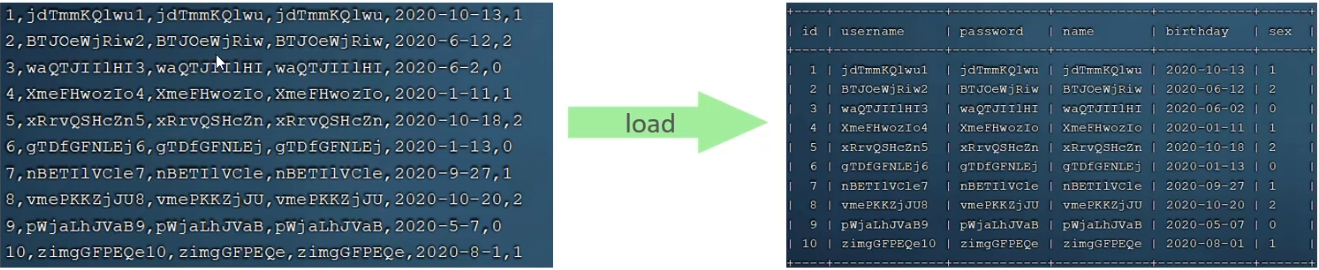

数据之间用’,'分隔,行用‘\n’分隔
视图:是一种虚拟存在的表,视图中的数据并不在数据库中真实存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成
通俗的讲,视图只保存了查询的 SQL 逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条 SQL 查询语句上
视图创建:
create [or replace] view 视图名 as select 语句 [with [cascaded | local] check option]
查询视图:

修改视图:

方式一和创建视图时的语句一样
区别在于:创建视图时,
or replace可以不加,但修改时必须加
删除视图:

创建视图时的检查选项_with [cascaded | local] check option_:
在创建视图时加上检查选项后,对视图进行增删改时,MySQL 会对视图定义的条件进行检查,增删改的数据必须满足视图定义语句的条件

local 和 cascaded 的区别:cascaded 会检查其上级视图的条件是否满足,即使上一级视图没有加视图检查选项,而 local 只关注当前视图的条件
只会向上级联!
视图是否可更新:

可更新:可以进行增删改
视图的作用:
由于数据库的授权最多到表,不能控制行和字段,因此若只想表中某几个字段对用户可见,就可以创建一个视图,其中只包含这几个字段,表中的另外字段用户就不可见了

存储过程:事先经过编译并存储在数据库中的 sql 语句集合
调用存储过程可以简化开发人员的工作,减少数据在数据库和应用服务器之间传输的次数,以提高数据处理效率
存储过程的思想就是 sql 语句的代码封装和重用
存储过程的特点:
存储过程的创建:

如:
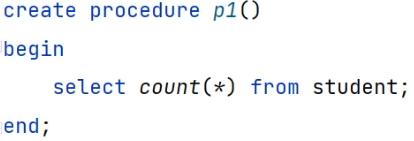
在命令行中创建存储过程时,默认分号为结束符,那么就会出问题
delimiter 符号可以指定结束符
如delimiter $$那么 MySQL 将会默认$$代替分号作为结束符
调用:
call 存储过程名(参数)
call p1()
查看存储过程:

删除:

表-段-区-页-行


每个表都有一个对应的 ibd 文件





内存结构:






磁盘结构:







后台线程: