该项目使用同步 IO 模拟 proactor 事件处理机制以及线程池来实现服务器的高并发。首先主线程创建绑定 socket 接口,设置端口复用并监听 TCP 连接,创建单例模式的线程池以及用于 IO 多路复用的 epoll 实例, 将 socket 的 **EPOLLIN** 事件注册到内核 ,主线程随后进入阻塞状态,直到内核检测到 IO 事件,主线程遍历 epoll 就绪列表,若有新的客户端请求建立连接,将该连接保存并在内核中为该连接注册监听。当客户端向服务器发送 http 请求时,主线程读取该请求,并将该请求的处理任务放入消息队列。通过信号量机制唤醒线程池中的一个等待线程。该线程通过互斥锁的方式从请求队列中安全地获取待处理请求,避免多线程访问共享资源时的竞争 。在工作线程中,采用有限状态机的方式解析 http 的请求报文,生成相应的响应报文头,利用内存映射将客户端请求的资源文件加载到缓冲区中,并在内核中注册 epollout 事件,随后该线程恢复等待状态。当 tcp 缓冲区可写时,内核通知主线程,由主线程将构建好的 http 响应发送给客户端。
通过定时的方式,当某个连接长时间未通信,向内核发送超时信号,内核捕获到该信号中断连接,以优化系统资源的利用。
使用 webbench 测试该服务器,成功实现上万连接的高并发
库——代码仓库
为什么要用库:代码保密、方便部署和分发

静态库的命名:以 lib 开头,不同操作系统的后缀不同,xxx才是库名称
libxxx.alibxxx.lib静态库制作:
.o 文件ar 工具(archive)将.o 文件打包:ar rcs libxxx.a xxx.o xxx.o r- 将文件插入备存文件中c- 建立备存文件s- 创建索引静态库使用:
一个 C 项目中往往包含include 目录(包含头文件)、lib 目录(包含库文件)、src包含源代码

对于静态库的使用,要与其头文件一起分发,头文件中声明了库文件的函数等信息,没有头文件就不知道这个库到底是干嘛的。
gcc -c add.c sub.c mult.c div.c -I ../include-I 指定头文件路径 ar rcs libsuanshu.a add.o div.o mult.o sub.o
gcc main.c -o suanshu -I ./include -L ./lib -l suanshu-I :头文件路径-L :库文件路径-l (小写的 L):库文件名称,注意这里的suanshu就是libsuanshu.a命名:
libxxx.so,是个可执行文件libxxx.dll制作:
.o 文件,得到与**位置无关的代码-fpic 或-fPIC 参数就能得到位置无关的代码gcc -shared a.o b.o -o libcalc.so -shared 参数制作动态库使用:与静态库一样,动态库的头文件也要一同分发。
gcc main.c -o main -I include/ -L lib/ -l calc
-I :指定头文件的路径
-L :指定动态库的路径
-l :指定动态库的名字
此时还需要将动态库加载到内存中才能成功执行编译完成的 main
可以通过**ldd**(list dynamic dependencies)来检查程序的动态库依赖关系

如何将动态库加载到内存中:
当系统加载可执行代码时候,能够知道其所依赖的库的名字,但是还需要知道绝对路径。此时就需要系统的动态载入器来获取该绝对路径。对于 elf 格式的可执行程序,是由 ld-linux.so 来完成的, 它先后搜索 elf 文件的 DT_RPATH段 ——> 环境变量 LD_LIBRARY_PATH ——> /etc/ld.so.cache 文件列表 ——>/lib/,/usr/lib 目录找到库文件后将其载入内存。
如何使动态载入器获得动态库的绝对路径:
DT_RPATH 不可被我们更改,那么就将动态库路径加入环境变量中:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/study/lib/libcalc.so
注意这种方式配置的环境变量只在当前终端下有效,关闭之后又得重新配置
如何永久配置:
.bashrc ,并在其中写入:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/study/lib/libcalc.so,并更新配置文件source .bashrc/etc/profile ,并写入export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/study/lib/libcalc.so2, 配置/etc/ld.so.cache 文件:
由于该文件是一个二进制文件,那么就要通过修改/etc/ld.so.conf 直接在其中写入动态库的绝对路径就行来配置/etc/ld.so.cache
/lib 或者/usr/lib 目录下,但是不推荐,因为这是系统库静态库:
优点:
缺点:
动态库:
优点:
缺点:加载速度较慢,发布程序时需要提供依赖的动态库
Makefile 文件定义了一系列规则来指定哪些文件需要先编译、后编译、重新编译,也可以在其中执行一些系统命令。
Makefile 主要用于自动化编译,只需要 make 命令就能自动编译,极大提高开发效率。
在 Makefile 中,其他规则默认都是为第一条规则服务的,即其他规则生成的目标若第一条规则中没有使用,那么就不会执行这条规则。
文件命名:Makefile
规则:一个 Makefile 文件由多个规则组成
目标 ...: 依赖 ...
命令
...
如:

工作原理:
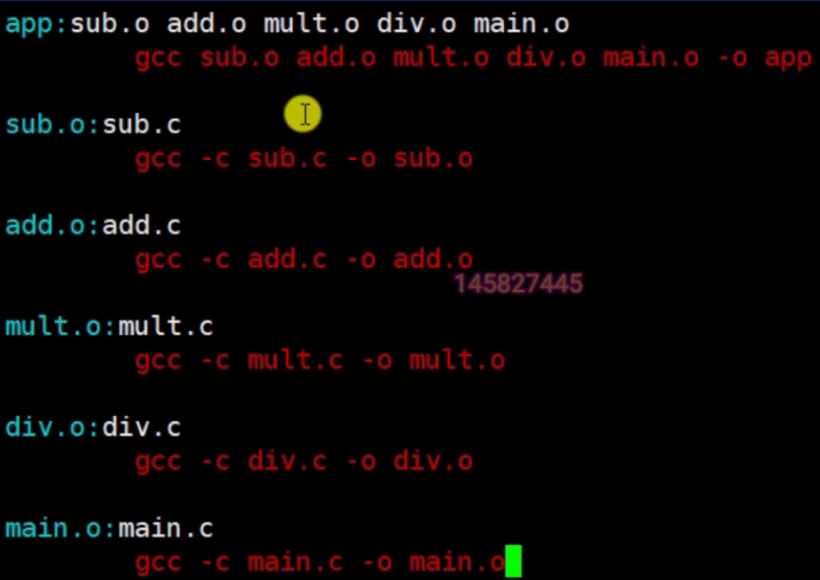
变量:
变量名=变量值,如var=hello$(变量名),如:$(var)AR:归档维护程序的名称,默认值arCC:C 编译器名称,默认值ccCXX:C++编译器名称,默认值 g++$@:目标的完整名称$<:第一个依赖文件的名称$^:所有的依赖文件如:

模式匹配:
通配符:%
如有下面格式相同的规则,那么就可以使用模式匹配
add.o:add.c
gcc -c add.c
div.o:div.c
gcc -c div.c
sub.o:sub.c
gcc -c sub.c
mult.o:mult.c
gcc -c mult.c
main.o:main.c
gcc -c main.c
上面 10 行直接写成
%.o:%.c
gcc -c $< -o $@
函数:
$(wildcard PATTERN...)
PATTERN:一个或多个目录下对应的某种类型的文件,若有多个目录(即多个参数),之间用空格隔开如: $(wildcard .c ./sub/.c)
$(patsubst <pattern>,<replacement>,<text>)
查找 text 中的单词是否符合模式 pattern,若匹配,则用 replacement 替换
pattern:可以包含通配符%,表示任意长度的字符串模式匹配%,则该 % 就是 pattern 中的 % 所代表的字符串replacement :表示用来替换的字符串text:查找的对象如:$(patsubst %.c, %.o,x.c bar.c)
调试准备工作:
-O 参数(不进行编译优化);使用 -g 参数(打开调试选项);尽量使用 -Wall 参数(用于打开所有的 warning)gcc -g -Wall program.c -o program 基本命令:
启动退出:
gdb 可执行程序quit给程序设置参数:(main 函数接受的来自用户输入的参数)
set args 10 20获取设置参数:
show argsGDB 使用帮助:help
查看当前文件代码:
list/l 从默认位置显示list/l 行号显示指定行上下文list/l 函数名 显示指定函数上下文查看非当前文件代码:
list/l 文件名:行号list/l 文件名:函数名这里的
list/l 是或者的意思
设置显示的行数:
show listset list 行数断点操作
设置断点:
break/b 行号break/b 函数名break/b 文件名:行号break/b 文件名:函数查看断点:
info/i break/b删除断点:
d/del/delete 断点编号设置断点无效:
dis/disable 断点编号设置断点生效:
ena/enable 断点编号设置条件断点:(一般用在循环的位置)
b/break 10 if i==5调试命令:
运行 GDB 程序:
start 程序停在第一行run 遇到断点才停下继续运行直到下一个断点:
c/continue单步调试:
n/next 不进入函数体s/step 会进入函数体finish 跳出函数体变量操作:
p/print 变量名 打印变量值ptype 变量名 打印变量类型自动变量操作:
display 变量名 自动打印指定变量的值i/info display 查看是否自动打印undisplay 编号 不自动打印其他:
set var 变量名=值 设置变量值until 跳出循环标准 C 库的 IO 函数

标准 C 库 IO 和 Linux 系统 IO 的关系:标准 C 库 IO 底层调用 Linux 系统 IO
虚拟内存(虚拟地址空间)

文件描述符

Linux 系统 IO 函数
**int open(const char *pathname,int flags);**
一般用于打开已存在的文件
pathname:文件路径flags:对文件操作权限的设置,可以设置多个,用|(按位或)连接O_RDONLY(可读)、O_WRONLY(可写)、O_RDWR(可读可写)O_CREAT文件不存在就创建新文件-1 ,可以在errno中设置错误信息
errno:属于 Linux 系统函数库,库里面的一个全局变量,记录的是最近的错误号错误号可以使用
perror函数来打印
**int open(const char *pathname,int flags,mode_t mode);**
可以用来创建一个新文件
mode:用来设置新文件的权限,比如 0777、0744 等mode & ~umask int close(int fd);
ssize_t read(int fd,void *buf,size_t count);
从文件描述符 fd中读取 count字节的数据到 buf缓冲区
count:指定每一次读取的字节数 ssize_t write(int fd,const void *buf,size_t count);
向文件描述符 fd所引用的文件中写入从 buf开始的缓冲区中写入 count字节的数据
off_t lseek(int fd,off_t offset,int whence);
根据指令 whence将文件指针偏移 offset
offset:偏移量whence:SEEK_SET:设置文件指针的偏移量 offsetSEEK_CUR:设置文件指针的偏移量:当前位置+offsetSEEK_END:设置文件指针偏移量:文件大小+offset lseek(fd,0,SEEK_SET) lseek(fd,0,SEEK_CUR) lseek(fd,0,SEEK_END) lseek(fd,100,SEEK_END) int stat(const char *pathname,struct stat *statbuf);
获取一个文件相关的信息,文件名、大小、权限、uid、gid、改动时间、创建时间等等
pathname:文件路径statbuf:结构体变量,用于保存获取到的文件信息
st_mode 变量:
如下图,除了文件类型,权限使用标志位来表示,文件类型使用编码表示,用掩码即S_IFMT对文件类型进行判断st_mode & S_IFMT
判断权限,只需要与权限对应的宏定义相与
Linux 中一共有七种文件类型。
大写的这些都是宏定义。

int lstat(const char *pathname,struct stat *statbuf);
用于获取软链接文件的信息,若使用 stat,那么就是软链接指向文件的信息
int access(const char *pathname,int mode);
用于判断某个文件是否具有某个权限,或者判断文件是否存在
mode:F_OK:文件是否存在R_OK:是否有读权限W_OK:是否有写权限X_OK:是否有执行权限 int chmod(const char *pathname,mode_t mode);
修改文件的权限
mode:需要修改的权限值,可以是比如 777、755 int chown(const char *pathname,uid_t owner,gid_t group);
用于改变文件的所有者和所属组
owner:要改变的用户 IDgroup:要改变的所属用户组 ID
/etc/passwd中包含了所有用户,以及其用户 ID 等信息
/etc/group中包含了所有的用户组,以及用户组 ID使用
id命令可以查看用户 ID 和所属组 ID

int truncate(const char *path,off_t length);
缩短或扩展文件的尺寸至指定大小
length:需要将文件大小改到 length 大小 int mkdir(const char *pathname,mode_t mode);
创建目录
mode:权限 int rmdir(const char *pathname);
删除一个目录
int rename(const char *oldpath,const char *newpath);
重命名文件或目录,且可以移动文件,相当于 mv
int chdir(const char *path);
修改当前的工作目录
char *getcwd(char *buf,size_t size);
获得当前工作目录的绝对路径
buf:缓冲区,用于存储绝对路径,一般是 char 类型的数组size:数组的大小 DIR *opendir(const char *name);
打开目录(流)
因为 Linux 中一切皆文件,目录也是文件
struct dirent *readdir(DIR *dirp);
读取目录中的数据

int closedir(DIR *dirp);
关闭目录流
int dup(int oldfd);
复制一个新的文件描述符,指向同一文件!
int dup2(int oldfd,int newfd);
重定向文件描述符,将旧的文件描述符指向 newfd 指向的文件
int fcntl(int fd,int cmd, ... /* arg */ );
对文件描述符根据 cmd 命令进行操作,其中有很多的功能,详细参见 man
fd:需要操作的文件描述符cmd:对文件描述符如何操作F_DUPFD:复制文件描述符,得到一个新的文件描述符F_GETFL:获取指定文件描述符文件的状态 flag,与 open 函数的 flag 是同一个东西,即O_RDONLY等F_SETFL:设置文件描述符的状态进程是正在运行的程序的实例
在操作系统中,进程是最基本的分配单元和执行单元
在同一个 CPU 上,进程看似是同时运行,实则是轮番穿插着运行,根据时间片的分配来运行不同的进程
进程的状态:
三态模型:就绪态、运行态、阻塞态
五态模型:新建态、就绪态、运行态、阻塞态、终止态
查看进程命令:ps aux
实时显示进程动态:top
杀死进程:kill 进程号、kill -信号 进程号
信号有哪些可以通过
kill -l来查看
进程号的范围:0~32767
init 进程是操作系统的第一个进程,除 init 进程外,其他进程都有父进程
进程组:多个进程相互关联
获取当前进程 ID: pid_t getpid(void);
获取父进程 ID: pid_t getppid(void);
pid_t fork(void);
通过复制当前的进程来创建子进程,父子进程运行在独立内存空间,但在虚拟地址空间中,用户区的内容相同(因为是复制父进程),内核内容也会复制,但是 PID 以及内存空间不同
父子进程的内容相同,因此父子进程若要执行不同的内容,则在 if 条件分支中加入不同的内容即可
fork 时,实际上使用的是读时共享,写时拷贝,即只有在父子进程要修改内容时,会拷贝一份,而只是读取时,两者共享相同的空间。这样可以减少资源浪费,提高运行效率
GDB 默认调试一个进程(父进程),也就是打断点等操作是在父进程中,子进程创建后的执行不受影响
可以通过设置 follow-fork-mode参数来选择调试父或子进程,
set follow-fork-mode child/parent
或者通过设置调试模式,将其他进程挂起,set detach-on-fork on(默认)/off
on 表示调试当前进程时,其他进程继续运行,off 则是挂起其他进程,挂起在 fork 的地方
在子进程挂起的情况下,如何切换进程:inferior 进程 num
调试时查看当前程序的进程:info inferiors
使某个进程脱离 GDB 的调试,即使得某个进程运行到结束detach inferiors 进程 num
exec 函数族:在该进程中调用另外一个可执行文件
通常的用法是:在父进程中创建一个子进程,在子进程中调用可执行文件,这样父子进程的内容不相同也不会相互影响(也就是子进程的内容被调用的可执行文件内容所替换)
exec 函数族中的函数执行成功后并不会返回(内容被可执行文件替换了,返回也没有意义,和金蝉脱壳一样),调用失败返回-1
C 标准库中有:execl,execlp,execle,execv,execvp,execvpe函数
Linux 系统调用中有:execve
exec 后面跟着字母的意思:
l:list,参数列表p:path,PATH 环境变量v:vector,存有各参数地址的指针数组的地址e:environment,存有环境变量字符串地址的指针数组的地址,可以在代码中自定义临时环境变量的数组作为参数 int execl(const char *pathname,const char *arg, ...);
pathname需要执行的指定文件args:执行可执行文件的所需的参数列表,第一个参数一般是可执行文件名,第二个参数往后,才是程序执行所需的参数列表,**NULL**结束(哨兵)如 execl("/bin/ps", "ps", "aux",NULL);
int execlp(const char *file,const char *arg, ...);
会到环境变量中找可执行文件
如: execlp("ps", "ps", "aux",NULL);
execl和execlp最常用
其他:
int execle(const char *pathname,const char *arg, ...,char *const envp[] */);
int execv(const char *pathname,char *const argv[]);
int execvp(const char *file,char *const argv[]);
int execvpe(const char *file,char *const argv[],char *const envp[]);
int execve(const char *pathname,char *const argv[],char *const envp[]);
进程退出,一般用标准 C 库的 exit
标准 C 库:exit void exit(int status);
系统调用:_exit void _exit(int status);
区别:exit在调用系统调用_exit 之前,会调用退出处理函数,并刷新 IO 缓冲区关闭文件描述符等操作。

孤儿进程:父进程已经结束,但子进程还在运行的进程
孤儿进程出现时,内核将其父进程设置为init ,而init进程会循环 wait()子进程结束,然后进行善后。
init 进程号为 1
僵尸进程:子进程已经结束,但是父进程没有回收其资源(为什么没有:可能时没空吧),就会产生僵尸进程(没人收尸)
每个进程结束时,其父进程会去将子进程空间中的用户数据释放。当子进程结束后,父进程并没有回收其资源。而系统的进程号有限,若有大量的僵尸进程产生,那么就会因为没有进程号可用而造成系统不能生成新的进程。
僵尸进程不能被 kill -9杀死
如何解决僵尸进程:杀死父进程,让僵尸进程被 init 托管
如何避免产生僵尸进程:在父进程中调用 wait()、 waitpid()得到子进程的退出状态的同时,彻底清除掉这个进程
wait和waitpid功能一致,等待子进程的结束并回收资源。每次调用,只能清理一个子进程,其区别:
wait():调用 wait的进程会被挂起(阻塞状态) pid_t wait(int *wstatus);
返回值:
- 成功:返回被成功回收的子进程 ID
- 失败或所有子进程都已经结束:-1
waitpid():回收指定进程号的进程,可以设置是否阻塞(默认阻塞) pid_t waitpid(pid_t pid,int *wstatus,int options);
参数:
- ` pid `:
>0 :回收指定进程号的进程
=0 :回收当前进程租的所有子进程
-1 :回收所有的子进程,相当于 wait()(最常用)
<-1 :回收指定进程组中的子进程,指定进程组为传入参数的绝对值
- wstatus:进程退出时的状态信息,传入一个 int 的指针来存储状态信息
进程退出的相关状态信息宏函数
WIFEXITED(status) 非 0,进程正常退出
WEXITSTATUS(status) 如果上宏为真,获取进程退出的状态(exit 的参数)
WIFSIGNALED(status) 非 0,进程异常终止
WTERMSIG(status) 如果上宏为真,获取使进程终止的信号编号
WIFSTOPPED(status) 非 0,进程处于暂停状态
WSTOPSIG(status) 如果上宏为真,获取使进程暂停的信号的编号
WIFCONTINUED(status) 非 0,进程暂停后已经继续运行
- ` optionns `:
0:阻塞(默认)
WNOHANG:非阻塞
options 中还有其他选项,但是用的不多
返回值:
- 成功:
>0 :被成功回收的子进程 ID
=0 :非阻塞状态,且还有指定的子进程没有结束
- 失败或所有子进程都已经结束:-1

进程间通信(IPC,inter processes communication):在不同进程间传递交互信息、状态等信息
通过进程间通信可以实现:数据传输、事件通知、资源共享、进程控制
Linux 中进程间通信的方式:

管道是内核维护的缓冲区
管道也是文件,具有读写操作,可以按照操作文件的方式来操作管道。
匿名管道没有实体文件,而有名管道有文件实体,但该实体文件不存储数据
管道中的数据相当于数据结构中的队列,先进先出,且数据传递方向是单向,一端写一端读(半双工)
管道读写数据的特点:
在管道阻塞 IO 模式下
SIGPIPE的信号,导致写端所在进程的异常终止如何将管道设置为非阻塞状态:通过 fcntl()函数设置读端或写端文件描述符的状态

匿名管道
匿名管道只能在具有公共先祖的进程之间使用,即父子进程、兄弟进程之间。
一般使用流程:先创建一个匿名管道,再 fork,父子进程共享同一个匿名管道
int pipe(int pipefd[2]);
参数:
pipefd[2]:传递两个表示管道读端和写端的文件描述符,其中 pipefd[0]:是管道的读端 pipefd[1]:是管道的写端返回值:
通过 ulimit -a命令查看系统内核的一些设置,如管道缓冲区大小

或者通过标准 C 库的函数 fpathconf()查看, long fpathconf(int fd,int name);
有名管道(FIFO)
Linux 中的七种类型的文件之中就有一个是管道文件(FIFO 文件)
可以在不相关的进程间通信
FIFO 文件中没有内容,内容放在内存中
一般使用流程:先创建有名管道,然后像文件一样操作,open、read、write
创建:mkfifo
直接使用系统命令 mkfifo就可以创建有名管道**
**或者在标准 c 库中
int mkfifo(const char *pathname,mode_t mode);
参数:
pathname:创建的管道名字(FIFO 文件名)mode:文件权限返回值:
通过内存映射,将磁盘内的内容映射到内存,改变内存中的内容,磁盘中的内容随之改变。
那么就可以将同一个文件中的内容映射到两个进程的内存中,
内存映射进行的进程间通信为非阻塞
也可以使用内存映射实现文件拷贝,且在内存中进行内存拷贝(mencpy)操作速度很快,但一般不用于文件拷贝
内存映射:mmap
void *mmap(void *addr,size_t length,int prot,int flags,int fd,off_t offset);
将一个文件或设备的数据映射到内存中
参数:
- ` addr `:一般为 NULL,内核指定内存地址
- ` length `:要映射的数据长度,建议使用文件的长度(可以使用` stat()`或 ` lseek()`来获取文件长度)
- ` prot `:对申请的内存映射区的操作权限
PROT_EXEC:执行权限
PROT_READ:读权限
PROT_WRITE:写权限
PROT_NONE:没有权限
一般是读写权限:PROT_READ | PROT_WRITE
- flags:
MAP_SHARED:映射区的数据会自动与磁盘文件进行同步
进程间通信必须要设置这个
MAP_PRIVATE:不同步,内存映射区的数据改变后,不会修改原文件,而是重新创建一个新文件(写时拷贝)
- fd:需要操作的文件描述符
- offset:偏移量,一般是 0,即不使用偏移,
prot 指定的权限必须
<=文件描述符权限偏移量必须是 4k 的整数倍
否则返回
MAP_FAILED
返回值:
- 成功:返回创建的内存的首地址
- 失败:返回 ` MAP_FAILED`
取消映射:munmap
int munmap(void *addr,size_t length);
参数:
- ` addr `:要释放的内存的首地址
- ` length `:要释放的内存大小,和 mmap 中的 length 参数值一样大小
返回值:
- 成功:0
- 失败:-1
使用内存映射实现进程间通信:
怎么往内存里读写数据:

匿名映射——只能用于父子进程间通信
使用内存映射也可以进行匿名映射,即不需要任何文件实体,在 flag 中加上MAP_ANONYMOUS,文件描述符参数使用-1.
mmap(NULL,len,PROT_READ | PROT_WRITE,MAP_SHARED | MAP_ANONYMOUS, -1,0)
信号是事件发生时对进程的通知机制。也可称为软件中断。是一种异步通信方式
产生信号的四种情况:
Ctrl+C查看系统定义的信号列表:kill -l
重点是前 31 个信号,后面的不用管
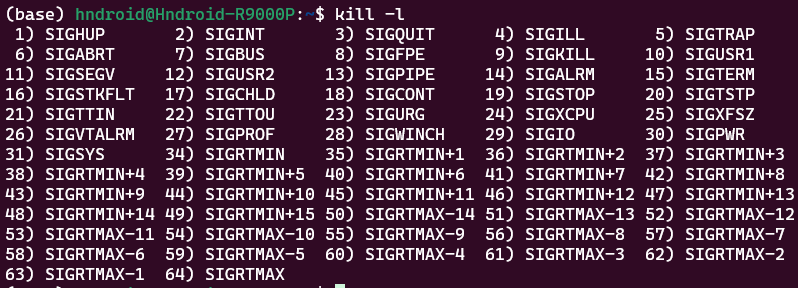
下面的信号,加粗的掌握就行



SIGKILL和SIGSTOP信号不能被捕捉、阻塞或者忽略,只能执行默认动作
信号的 5 种默认处理动作:
信号发送的状态:
信号相关函数:kill、raise、abort、alarm、setitimer
int kill(pid_t pid,int sig);
给某个进程或进程组发送信号
参数:
- ` pid `:
>0 :将信号发送给指定的进程号
=0 :将信号发送给当前的进程组中所有进程
-1 :将信号发送给每一个有权限接受这个信号的进程
<-1 :发送给指定进程组,进程组号取绝对值
- sig:需要发送信号的编号或者宏值,0 表示不发送任何信号
返回值:
- 成功:0
- 失败:-1
如: kill(getpid(),9)
int raise(int sig);
给当前进程发送信号
返回值:
- 成功:0
- 失败:非 0
void abort(void);
给当前进程发送 SIGABRT信号,杀死当前进程
unsigned int alarm(unsigned int seconds);
设置定时器,倒计时到 0 时,给当前进程发送一个信号 SIGALARM
每一个进程都有且只有一个定时器
不会阻塞,可以继续往下执行
该定时器与进程的状态没有任何关系,无论何时,只要启用,那就一直定时
参数:
- ` seconds `:倒计时时长,单位秒
若参数为 0,则不进行定时,也可以通过 alarm(0)来取消定时器
返回值:
- 之前没有定义定时器,则返回 0
- 之前已有定时器,返回之前的定时器剩余时间
也就是重复设置定时器,只遵循第一个设置的定时器倒计时
SIGALARM信号:默认终止当前进程
int setitimer(int which,const struct itimerval *new_value,struct itimerval *old_value);
设置定时器,可以替代 alarm 函数,精度比 alarm 高,精度微秒,可以实现周期性定时
参数:
- ` which `:定时器以什么时间定时
**ITIMER_REAL**:真实时间,定时结束发送 SIGALRM,最常用
ITIMER_VIRTUAL:用户时间,定时结束发送SIGVTALRM
ITIMER_PROF:以该进程在用户态和内核态下所消耗的时间来计算,定时结束发送SIGPROF
- new_value:设置定时器的属性,如:10s 后,开始指定定时器,周期为 2s
//定时器的结构体
struct itimerval {
struct timeval it_interval; /* 周期执行的间隔时间 */
struct timeval it_value; /* 延迟执行定时器,延迟多长时间 */
};
//时间的结构体
struct timeval {
time_t tv_sec; /* 秒 */
suseconds_t tv_usec; /* 微秒 */
};
- ` old_value `:记录上一次定时的时间参数,一般不使用,指定` NULL `
返回值:
- 成功:0
- 失败:-1
alarm 和 setitimer 之间的区别:alarm 是定时一次,而 setitimer 是周期定时
信号捕获——signal、sigaction
**SIGKILL** 和 **SIGSTOP**不能被捕捉也不能被忽略
最好使用 sigaction,因为 signal 是 ANSI c 下的标准,而 sigaction 通用
signal sighandler_t signal(int signum,sighandler_t handler);
其中 handler回调函数的类型是: void(*sighandler_t)(int);函数指针,
正常定义函数,返回值为 void,参数类型为 int 的函数就行,直接把函数名放到 signal 中作为参数。这里的 int 参数是信号的编号,不需要人为定义,内核会给出
设置某个信号的捕捉行为
参数:
- ` signum `:要捕捉的信号,一般使用信号宏值
- ` handler `:捕捉到的信号如何处理
SIG_IGN:忽略信号
SIG_DFL:使用信号默认行为
回调函数:由程序员自定义处理信号的函数,最终由内核调用
回调函数:由程序员实现,函数的类型根据实际需求,看函数指针的定义。不由程序员调用,而是当信号产生时,由内核调用。函数指针是实现回调的手段,函数实现之后,将函数名放到函数指针的位置就可以
返回值:
- 成功:返回上一次注册的信号处理函数的地址,第一次调用返回` NULL `
- 失败:` SIG_ERR `
sigaction int sigaction(int signum,const struct sigaction *act,struct sigaction *oldact);
捕捉信号并检查或改变信号的处理
参数:
- ` signum `:要捕捉的信号,一般使用信号宏值
- ` act `:捕捉到信号之后的处理动作
- ` oldact `:上一次捕捉到信号的相关设置,一般写` NULL `
//sigaction 结构体
struct sigaction {
//函数指针,指向信号处理函数
void(*sa_handler)(int);
//不常用,也是函数指针
void(*sa_sigaction)(int,siginfo_t *,void *);
// 临时阻塞信号集,在信号捕捉函数执行过程中,临时阻塞某些信号
sigset_t sa_mask;
// 使用什么方式对捕获到的信号进行处理
// 0:使用 sa_handler
// SA_SIGINFO:使用 sa_sigaction
int sa_flags;
// 被废弃,不用管
void(*sa_restorer)(void);
};
返回值:
- 成功:0
- 失败:-1
信号集——结构体类型**sigset_t**
在 PCB(进程控制块)中,有两个非常重要的信号集:阻塞信号集和未决信号集,内核通过标志位(位图、位向量)的方式实现。
未决信号集:从产生到信号处理之前的信号集合。未决信号集不能被用户修改,只能读取
阻塞信号集:阻止某个信号被处理(暂时的,相当于延后处理信号),防止某些敏感操作被信号打断。阻塞信号集可以通过系统调用来修改。
借助信号集操作函数可以对 PCB 中的这两个信号集进行修改
信号集如下,橙色的才是内核中的信号集位图表示,灰色的只是注释。

**信号集工作流程:**以 Ctrl+c为例
Ctrl+c,产生一个 SIGINT信号 SIGINT信号未处理阻塞信号集默认不阻塞任何信号,可以使用 API 来设置
由于未决信号集只能记录一个同一种信号,若有多个同样的信号同时产生,那么只会有一个进入未决信号集,其他的将被舍弃。
信号集相关操作函数:
sigemptyset int sigemptyset(sigset_t *set);
清空信号集中的数据,将信号集中所有标志位置 0
参数:
- ` set `:传出参数,需要操作的信号集
返回值:
- 成功:0
- 失败:-1
sigfillset int sigfillset(sigset_t *set);
将信号集中所有标志位置 1
sigaddset int sigaddset(sigset_t *set,int signum);
设置信号集中的某个信号对应标志位为 1,表示阻塞这个信号
参数:
- ` signum `:需要设置阻塞的信号
sigdelset int sigdelset(sigset_t *set,int signum);
设置信号集中的某个信号对应标志位为 0,表示不阻塞这个信号
sigismember int sigismember(const sigset_t *set,int signum);
判断某个信号是否阻塞
返回值:
- ` 1 `:阻塞
- ` 0 `:不阻塞
- `-1 `:失败
**sigemptyset**、**sigfillset**、**sigaddset**、**sigdelset**、**sigismember** 以上的五个函数都是对自定义信号集的操作
如何对内核中的信号集进行操作:在设置完自定义的信号集后,调用 sigprocmask() 来设置内核中的阻塞信号集
sigprocmask int sigprocmask(int how,const sigset_t *set,sigset_t *oldset);
将自定义信号集中的设置,设置到内核中的阻塞信号集中
参数:
- ` how `:如何对内核阻塞信号集进行处理
SIG_BLOCK:将用户设置的阻塞信号添加到内核中,也就是阻塞信号集 | 自定义信号集
SIG_UNBLOCK:根据用户设置的自定义信号集,对内核中的阻塞信号解除阻塞,也就是阻塞信号集 & ~自定义信号集
SIG_SETMASK:直接使用自定义信号集覆盖内核中的阻塞数据集
- set:已经设置好的用户自定义数据集
- oldset:保存的以前的阻塞信号集的状态,一般写NULL
返回值:
- 成功:0
- 失败:-1
sigpending int sigpending(sigset_t *set);
获取内核中的未决信号集
参数:
- ` set `:传出参数,保存未决信号集中的数据
返回值:
- 成功:0
- 失败:-1
**SIGCHLD**信号
父进程以下情况会接受到内核发来的 SIGCHLD信号,父进程默认会忽略该信号:
SIGSTOP信号暂停 SIGCONT后唤醒时这样可以解决僵尸进程的问题,通过捕获 SIGCHLD信号来处理,这样就不需要调用 wait(),也就不会阻塞。
共享内存允许多个进程共享物理内存的同一块区域(被称为段)
共享内存机制无需内核介入,效率高
共享内存中的数据对所有共享同一个段的进程可用
共享内存使用流程
shmget()创建或获取一个共享内存段 shmat()将该进程与共享内存段关联 shmdt()取消关联 shmctl()删除共享内存段所有进程都与该共享内存段取消关联才可以删除,一个进程执行删除指令就可以
相关函数
shmget()shared memory get int shmget(key_t key,size_t size,int shmflg);
创建一个新的共享内存段,或获取一个已有的共享内存段标识
新创建的内存段中的数据都会被初始化为 0
参数:
- ` key `:通过这个找到或创建一个共享内存,一般用 16 进制表示,非 0
- ` size `:共享内存的大小
- ` shmflg `:定义访问权限和附加属性
附加属性:
IPC_CREAT:创建共享内存
IPC_EXCL:判断共享内存是否存在,需要和IPC_CREAT一起使用
如:IPC_CREAT | IPC_EXCL | 0664
返回值:
- 成功:返回共享内存的引用 ID,用于操作共享内存
- 失败:-1
shmat()shared memory attach void *shmat(int shmid,const void *shmaddr,int shmflg);
将当前进程和共享内存进行关联
参数:
- ` shmid `:共享内存的标识(ID),由` shmget `返回
- ` shmaddr `:申请的共享内存的起始地址,一般指定 NULL,由系统自动分配
- ` shmflg `:对共享内存的操作权限
SHM_RDONLY:读权限,必须得有
0:读写权限
返回值:
- 成功:共享内存的起始地址
- 失败:-1
shmdt()shared memory dettach int shmdt(const void *shmaddr);
将当前进程与共享内存解除关联
参数:
- 共享内存起始地址
返回值:
- 成功:0
- 失败:-1
shmctl()shared memory control int shmctl(int shmid,int cmd,struct shmid_ds *buf);
对共享内存进行操作,主要是用来删除共享内存
参数:
- ` shmid `:共享内存 ID
- ` cmd `:要做的操作
IPC_STAT:获取共享内存的当前状态IPC_SET:设置共享内存的状态IPC_RMID:标记共享内存被销毁
buf:传出参数,需要设置或者获取的共享内存的属性信息IPC_STAT:在 buf 中存储数据IPC_SET:buf 中需要初始化数据,设置到内核中IPC_RMID:没有用,传递 nullftokfile tokenkey_t ftok(const char *pathname,int proj_id)
根据指定的路径名和 int 值,生成一个共享内存的 key
这里的 key 指的就是
shmget中的第一个参数 key
参数:
- ` pathname `:指定一个路径
- ` proj_id `:int 类型的值,但是系统调用只会使用其中 8 个位,
范围:0-255,我们一般指定一个字符,如‘a’
返回值:
- 成功:生成的 key
- 失败:-1
操作系统如何知道一块共享内存被几个进程关联:
struct shmid_ds,该结构体中有一个成员shm_nattach,记录了关联的进程个数ipcs命令ipcs -a:列出所有进程间通信的信息,有消息队列、共享内存段、信号量数组ipcs -m:查询共享内存的信息ipcs -q:消息队列ipcs -s:信号量当共享内存的
key为 0 时,表示该共享内存已被标记删除
能否在多个进程中调用**shmctl**来删除共享内存
shmctl只是标记删除,并不是真正删除,只有等关联进程为 0 使才会删除共享内存。共享内存和内存映射的区别:
终端
echo $$: 打印当前终端的进程号
tty:当前终端的路径
默认情况下(即没有重定向的情况下),每个进程的标准输入stdin、标准输出stdout、标准错误输出stderr都指向当前终端,进程从标准输入即用户键盘输入读取,标准输出和标准错误输出指向当前显示器
在终端中键入ctrl+c向前台进程发送SIGINT信号; ctrl+\向前台进程发送 SIGQUIT信号
进程组和会话
进程组是一组相关进程的集合,其中的进程共享一个进程组标识符(PGID),PGID = 创建改进程组的进程号,也就是进程组的第一个进程。fork 出的进程继承父进程所属的 PGID
进程组生命周期:由首进程创建开始,到最后一个成员进程退出结束
会话
会话是一组相关进程组的集合
会话 ID=会话首进程 ID,也就是创建该会话的进程 ID
一个会话中所有进程共享一个控制终端,而一个控制终端最多只能控制一个会话
进程组和会话使得 shell 终端可以更好的管理进程
相关函数
pid_t getpgrp(void);
获取当前进程的进程组 ID
pid_t getpgid(pid_t pid);
获取指定进程的进程组 ID
int setpgid(pid_t pid,pid_t pgid);
设置指定进程、进程组的进程组 ID
pid_t getsid(pid_t pid);
获取会话 ID
pid_t setsid(void);
设置会话 ID
守护进程(daemon 进程、精灵进程)
Linux 中的后台服务进程,命名通常以 d 结尾
守护进程具备下列特征:
Linux 的大多数服务器就是用守护进程实现的。比如,Internet 服务器 inetd,Web 服务器 httpd 等
守护进程的创建步骤
这样子进程 ID 就不会和进程组 ID 相同
setsid()开启一个新会话这样守护进程就不会被控制终端控制,能运行在后台
umask,以确保守护进程创建文件和目录是拥有权限。这一步是可以省略\ dup2()将 0、1、2 重定向到 /dev/null 中文件描述符 0、1、2 分别表示标准输入、标准输出和标准错误输出
/dev/null是一个特殊的文件,所有写入都被丢弃
其中第一步和第二部以及核心业务逻辑最为重要,其他都是可有可无
一个进程可以包含多个线程。同一个程序中的所有线程均会独立执行相同程序,且共享同一份全局内存区域,其中包括初始化数据段、未初始化数据段,以及堆内存段。
**进程是 CPU 分配资源的最小单位,线程是操作系统调度执行的最小单位。 **
线程是轻量级的进程(LWP:Light Weight Process),在 Linux 环境下线程的本质仍是进程。
查看指定进程的线程:ps -Lf 进程号
为什么要使用线程:
一般情况下,main 函数是主线程,创建的进程是子线程
由于pthread.h并不是标准 c 库,因此编译时要加上-pthread 参数
pthread_create int pthread_create(pthread_t *thread,const pthread_attr_t *attr,void * (*start_routine) (void *),void *arg);
创建线程
参数:
- ` thread `:传出参数,线程创建成功后,子线程的 id 被写到该变量
- ` attr `:设置线程的属性,一般使用默认值 NULL
- ` start_routine `:函数指针,子线程的处理逻辑代码
- ` arg `:回调函数的参数,提供给` start_routine `使用
void * (*start_routine) (void *)就代表函数指针,也就是回调函数
返回值:
- 成功:0
- 失败:错误号 ` errnum`(非 0)
线程中的错误号和之前的 errno 不一样,不能使用 perror 来打印,应该使用
char * strerror(interrnum)
pthread_self pthread_t pthread_self(void);
获取当前线程的线程 ID
pthread_equal int pthread_equal(pthread_t t1,pthread_t t2);
比较两个线程的线程 ID 是否相等
线程 ID pthread_t 的类型是 long int,那么为什么不能直接使用
==来进行比较呢?因为不同操作系统的
pthread_t的定义可能不同
pthread_exit void pthread_exit(void *retval);
终止一个线程,在哪个线程调用就终止哪个线程
参数:
- ` retval `:传递一个指针作为一个返回值,可以在` pthread_join `中获取到。如果不需要该参数可以指定` NULL `
这里的retval最好是传入一个全局变量,因为局部变量当线程退出后,栈空间会清空
没有返回值!
使用
pthread_exit终止线程,对其他线程也没有任何影响,即使终止的是主线程,
pthread_join int pthread_join(pthread_t thread,void **retval);
和一个已经终止的线程进行连接,用于回收子线程的资源,和 wait()功能类似
这是阻塞函数,且一次调用只能回收一个子线程。一般在主线程使用
参数:
- ` thread `:需要回收子线程的线程 ID
- ` retval `:接收子线程退出时返回的值,不需要可以传递` NULL `,注意这里是二级指针
返回:
- 成功:0
- 失败:错误号` errnum `(非 0)
pthread_detach int pthread_detach(pthread_t thread);
分离一个线程,被分离的线程在终止的时候会自动释放资源返回给系统
不能多次分离一个线程,也不能去连接一个已经分离的线程
参数:需要分离的线程的 ID
返回:
- 成功:0
- 失败:错误号 ` errnum`(非 0)
pthread_cancel int pthread_cancel(pthread_t thread);
取消线程(让线程终止)
并不是立刻终止进程,而是当子进程执行到一个**取消点(cancellation point)**时,线程才会终止
取消点:系统规定的一些系统调用
线程属性操作函数
线程属性结构体类型:**pthread_attr_t**
先初始化,用完销毁
pthread_attr_initint pthread_attr_init(pthread_attr_t *attr);
初始线程属性变量
pthread_attr_destroy int pthread_attr_destroy(pthread_attr_t *attr);
释放线程属性的资源
pthread_attr_getdetachstate int pthread_attr_getdetachstate(const pthread_attr_t *attr,int *detachstate);
获取线程分离的状态属性
pthread_attr_setdetachstate int pthread_attr_setdetachstate(pthread_attr_t *attr,int detachstate);
设置线程分离的状态属性
参数:
- ` detachstate `:要设置的状态属性,默认可分离可连接
PTHREAD_CREATE_DETACHED:设置线程分离
PTHREAD_CREATE_JOINABLE:设置线程连接
互斥量有两种状态:已锁定(locked)和未锁定(unlocked)。任何时候,至多只有一个线程可以锁定该互斥量。试图对已经锁定的某一互斥量再次加锁,将可能阻塞线程或者报错失败,具体取决于加锁时使用的方法。
一旦线程锁定互斥量,随即成为该互斥量的所有者,只有所有者才能给互斥量解锁。一般情况下,对每一共享资源(可能由多个相关变量组成)会使用不同的互斥量,
线程对互斥量的使用流程:针对共享资源锁定互斥量 --> 访问共享资源 --> 对互斥量解锁
在共享资源(临界区)之前加锁,之后解锁

互斥量相关操作
互斥量类型:pthread_mutex_t
pthread_mutex_initint pthread_mutex_init(pthread_mutex_t *restrict mutex,const pthread_mutexattr_t *restrict attr);
初始化互斥量
参数:
- ` mutex `:需要初始化的互斥量
- ` attr `:互斥量相关的属性
restrict:C 语言的修饰符,被修饰的指针不能由另外一个指针进行操作
pthread_mutex_destroyint pthread_mutex_destroy(pthread_mutex_t *mutex);
释放互斥量的资源
pthread_mutex_lockint pthread_mutex_lock(pthread_mutex_t *mutex);
加锁
阻塞函数,若已有线程加锁,其他线程阻塞,等待
pthread_mutex_trylock int pthread_mutex_trylock(pthread_mutex_t *mutex); ****
尝试加锁,若加锁失败,不会阻塞,直接返回
非阻塞函数
pthread_mutex_unlockint pthread_mutex_unlock(pthread_mutex_t *mutex);
解锁
注意,这里互斥锁锁上的不是一个变量,而是在加锁和解锁之间的一段代码,也就是临界区
死锁
多个线程因争抢共享资源而导致相互等待的现象,若没有外力作用,将一直这样下去,那么称系统处于死锁状态,或产生了死锁
产生死锁的几种情况:
lock,那么就会形成死锁。
当程序对于共享资源的读操作需求占比大,而很少进行写操作时,可以使用读写锁,效率比使用互斥锁高,虽然效果好像差不多。
特点:
读写锁相关操作
读写锁类型: pthread_rwlock_t
pthread_rwlock_init int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t *restrict attr);
初始化读写锁
pthread_rwlock_destroy int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
销毁读写锁,释放资源
pthread_rwlock_rdlock int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
加读锁
pthread_rwlock_tryrdlock int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
尝试加读锁
pthread_rwlock_wrlock int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
加写锁
pthread_rwlock_trywrlock int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
尝试加写锁
pthread_rwlock_unlock int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
解锁
下面介绍的条件变量和信号灯并不能保证线程共享资源的安全问题,需要配合互斥锁进行使用
满足某些条件可以使得线程阻塞
与互斥量配合使用
条件变量类型:pthread_cond_t
pthread_cond_init int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);
初始化条件变量
pthread_cond_destroyint pthread_cond_destroy(pthread_cond_t *cond);
销毁条件变量,释放资源
pthread_cond_waitint pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
线程等待
阻塞函数
当调用该函数线程阻塞时,会临时进行解锁。等待结束后,又会进行加锁。因此不需要人为的加锁解锁,其他线程也可以在该线程阻塞时占用锁
参数:
- ` mutex `:互斥量
pthread_cond_timedwait int pthread_cond_timedwait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex,const struct timespec *restrict abstime);
线程等待规定的具体时间
阻塞函数
pthread_cond_signal int pthread_cond_signal(pthread_cond_t *cond);
唤醒一个或多个等待线程
pthread_cond_broadcast int pthread_cond_broadcast(pthread_cond_t *cond);
唤醒所有等待线程
当信号灯全灭,即信号量为 0,就使得线程阻塞
信号灯类型:sem_t
sem_initint sem_init(sem_t *sem,int pshared,unsigned int value);
初始化信号量
参数:
- ` sem `:信号量
- ` pshared `:决定使用在线程间还是进程间
0:线程间
!=0 :进程间
- value:信号量的值
2. sem_destroy
int sem_destroy(sem_t *sem);
销毁信号量,释放资源 0
sem_wait int sem_wait(sem_t *sem);
调用一次,信号量的值 -1,当信号量为 0 时,线程阻塞进入等待状态,直到信号量不为 0
sem_trywaitint sem_trywait(sem_t *sem);
尝试将信号量 -1,信号量为 0 也不会阻塞线程
sem_timedwait int sem_timedwait(sem_t *sem,const struct timespec *abs_timeout);
等待多长时间
sem_post int sem_post(sem_t *sem);
调用一次,信号量的值 +1,唤醒一个阻塞线程
sem_getvalueint sem_getvalue(sem_t *sem,int *sval);

生产者消费者模式可能会遇到的问题:
1. 仓库满了,生产者线程还在生产
2. 仓库空了,消费者线程还在消费
可以通过条件变量和信号量来解决,
字节序:字节在内存中存储的顺序
TCP/IP 规定网络字节序采用大端传输
在主机发送数据时,统一先转换为大端字节序,在网络中传输。而接收主机根据自身的字节序类型决定是否转换
主机——网络字节序转换函数
#include <arpa/inet.h>
一般用于转换端口(2 字节)
uint16_t htons(uint16_t hostshort);
uint16_t ntohs(uint16_t netshort);
一般用于转换 IP(4 字节)
uint32_t htonl(uint32_t hostlong);
uint32_t ntohl(uint32_t netlong);
h:host n:network s:short l:long
不用自行判断主机的大小端,函数会自行处理
socket
Linux 下一切皆是文件,socket 连接后,与操作文件的方式相似
socket 地址是封装了 IP 地址和端口号等信息的结构体
通用 socket 地址的结构体类型为 sockaddr、sockaddr_storeage,但由于使用麻烦,诞生了专用 socket 地址
**sockaddr_in**sockaddr_in6记住
sockaddr_in即可,其他了解
但是,所有专用 socket 地址类型使用时要转换为通用 socket 地址**sockaddr**类型,使用强制转换即可

sa_family_t类型为地址族,如下


点分 IP 地址表示(即 192.1.1.1 的形式)与网络字节序整数之间的转化,适用于 IPV4 和 IPV6
inet_pton() in_addr,也就是结构体 sockaddr_in中的 inaddr成员,所有定义一个 in_addr类型的 dst 接收就行。 inet_ntop()

TCP 通信流程
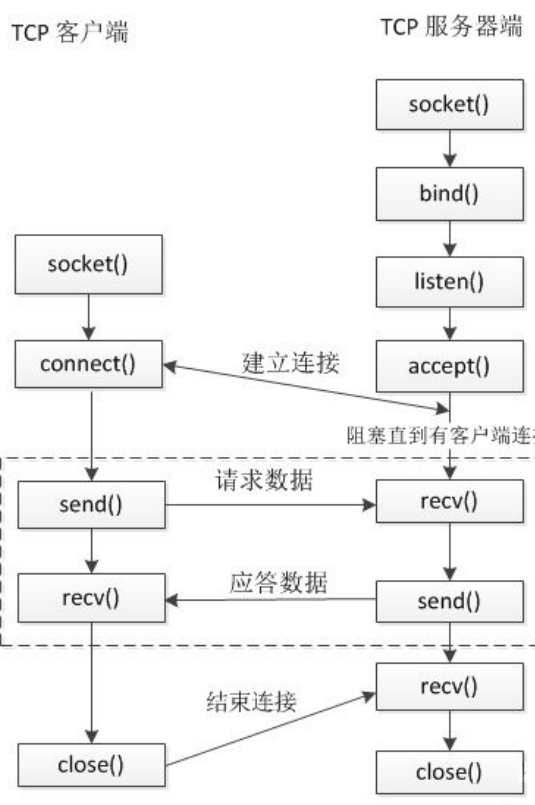

套接字函数


socket()返回的文件描述符与 accept 返回的文件描述符不同
socket 的用于 accept 连接,当有连接请求来时,缓冲区有数据
而 accept 是用于接收数据和发送数据
TCP 报文
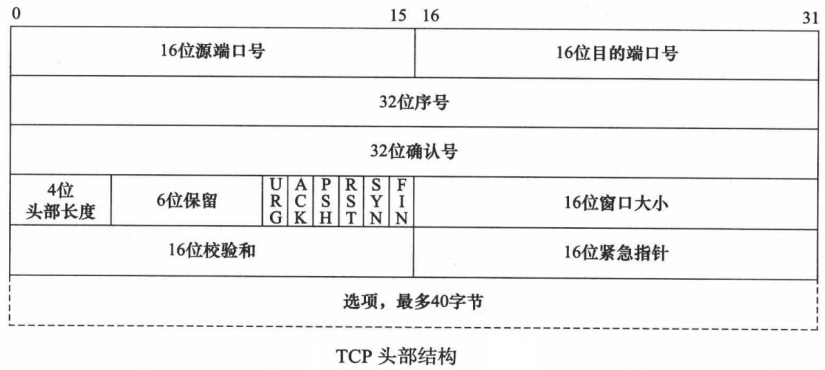

三次握手

四次挥手

滑动窗口
用于流量控制、拥塞控制,
TCP 的状态转换

端口复用
解决服务器所用的端口未释放导致服务器不能正常启动

IO 多路复用(IO 多路转接)——面试必问
**IO 多路复用使得程序能监听多个文件描述符,**提高程序性能
主流的 IO 模型:
对 IO 操作阻塞,不能执行下面的语句
对 IO 操作不阻塞,通过轮询的方式进行 IO 操作。
举个例子就是 read 函数,BIO 是阻塞在这,而 NIO 是通过循环一遍遍的执行 read,也就是轮询
委托内核对 IO 操作进行管理
阻塞函数
工作原理:使用标志位的方式



在 select 之前,要先将需要检测的文件描述符调用 FD_SET放进列表中(置为 1),select 后若对应的文件描述符没有内容需要读入而置为 0,下一次 select 之前,还需要先置为 1(可以使用一个临时列表作为 select 返回,另外一个列表用于维护需要检测的文件描述符)
一般是检测读缓冲区是否有数据,很少去检测写缓冲区是否还有空间可写



使用结构体数组而非位向量的列表




UDP 通信流程

[附件:UDP 通信、本地套接字.pdf](./attachments/ALmXIsk2BO_ErH6H/UDP 通信、本地套接字.pdf)
重点看里面的事件处理模式,本项目使用 proactor 处理模式